Example: Dropbox OCR Workflow
This example demonstrates a complete OCR workflow that automatically processes documents from Dropbox, extracts text using PlemeoOCR, and stores the results in your plemeo.ai Knowledge Base.
Workflow Overview
A typical OCR use case combined with Dropbox consists of the following steps:
- Webhook Trigger → Starts the workflow manually or automatically
- Dropbox: List Folder → Lists all files in a specified Dropbox folder
- Dropbox: Download File → Downloads the relevant file (e.g. a PDF)
- PlemeoOCR Node → Detects and extracts text from the document
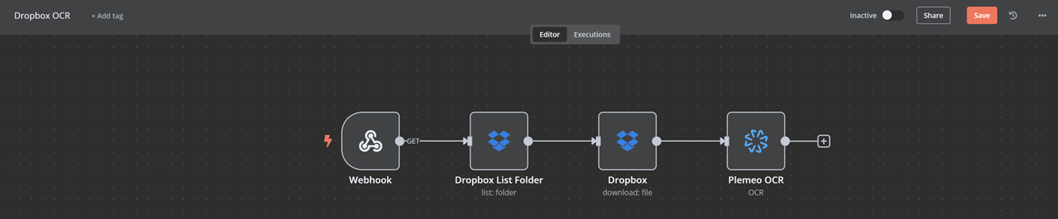 Complete Dropbox OCR workflow in n8n
Complete Dropbox OCR workflow in n8n
Step-by-Step Implementation
Step 1: Webhook Trigger
Initiates the workflow when called
Step 2: Dropbox - List Folder
Retrieves a list of files from a specified Dropbox folder
Step 3: Dropbox - Download File
Downloads each file for OCR processing
Step 4: PlemeoOCR Node
Extracts text from the downloaded document using your personal API key
Automatic Knowledge Base Storage
After the workflow completes, extracted text is automatically saved to your plemeo.ai Knowledge Base and becomes searchable through the AI chatbot.
What's Next?
- Troubleshooting - Resolve common workflow issues
- Usage Guide - Learn more about node configuration
- Back to Overview - Return to PlemeoOCR main page
Additional Resources
n8n Community
- n8n Community Forum - Get help with workflow design
- n8n Documentation - Learn more about n8n features
File Processing Tips
- Document Scanning: Best practices for creating OCR-friendly documents
- File Organization: Structure your Dropbox/cloud storage for efficient processing
- Quality Control: Validate OCR results before final processing